En esta serie de entradas vamos a revisar como ver reglas de firewall/cortafuegos en nuestras maquinas Linux, esto a pesar que no es común verlo en local, generalmente se delega este tema a los equipos de redes.
En esta ocasión vamos a centrarnos en distribuciones basadas en RHEL y que usan el paquete “firewalld”, en entradas posteriores abordaremos ufw para ubuntu, nft para debian y el descontinuado iptables que aun se encuentra en muchos sistemas.
el comando básico para ver todas las reglas en ejecución sería el siguiente:
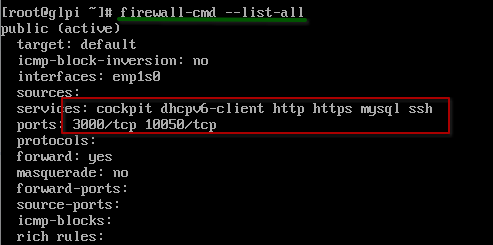
firewall-cmd –list-all
En el anterior comando podemos observar que se tiene abiertos los servicios de http, https, mysql, entre otros, así como los puertos 3000 en TCP y 10050 también en TCP.
De lo anterior podemos inferir que podemos declarar reglas haciendo referencia a servicios, siempre y cuando conozcamos sus nombres en /etc/services, o bien agregar un puerto diferente junto con su protocolo.
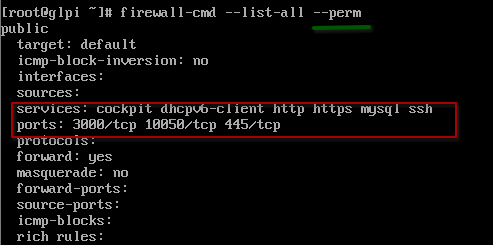
Para poder ver las reglas que sobrevivirán a un reinicio sencillamente sería agregarle la opción –perm
firewall-cmd –list-all –perm
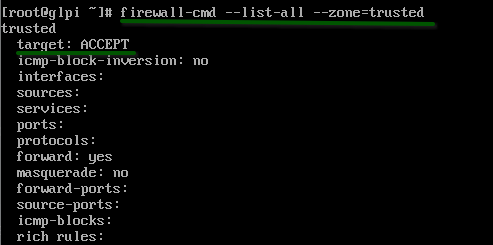
Por ultimo en caso que tengamos zonas adicionales en firewalld, podemos ver solo la reglas de esa zona.
firewall-cmd –list-all –zone=trusted
En la anterior captura podemos observar que la zona trusted no tiene reglas definidas, pero por lo contrario su target es ACCEPT, es decir cualquier interfaz que asignemos a la zona trusted, todo su trafico será permitido.
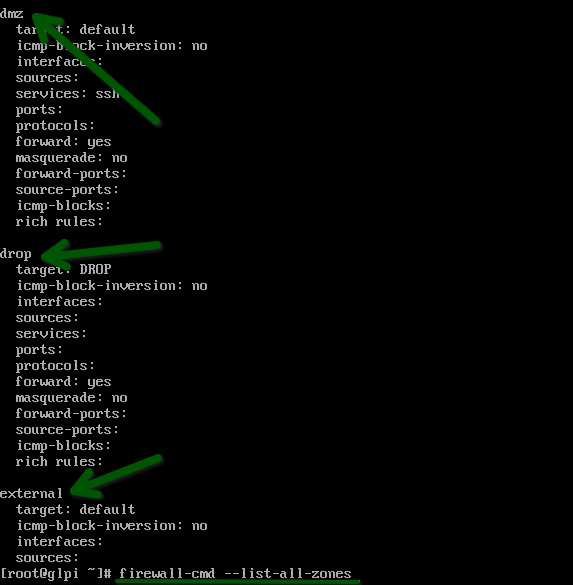
Por ultimo veremos el comando para listar las zonas definidas dentro de firewalld
firewall-cmd –list-all-zones
Como podemos observar se listan algunas interfaces definidas por el firewall.
Con esto terminamos la entrada de este post, como siempre se recomienda consultar las paginas man de cada comando así como recordar si hay alguna duda nos pueden escribir a través de nuestros canales.
Bienvenidos a una nueva entrada en nuestro blog empresarial, esperamos que este articulo sea de ayuda.
En esta ocasión nos alejaremos momentáneamente de la linea regular y nos centraremos en el segmento de la video vigilancia, particularmente con la marca Dahua.
Por lo general el adquirir una cámara para nuestro uso personal no representa mayor problema, sin embargo cuando necesitamos algunas configuraciones particulares la situación cambia y es que en este caso se requiere que una o varias cámaras dahua se puedan consumir a través de un proxy reverso que trabaja con apache.
En primera instancia la configuración parecería sencilla, ya que solo sería definir unas entradas de proxypass y ya quedaría. Pero no, dahua no nos lo coloca sencillo y es que la forma en que esta construido el servidor web de la cámara es complejo, las rutas están cargadas dentro de archivos javascript, mismos que son llamados por scripts previamente cargados, lo que anula la funcionalidad del proxy reverso.
Por lo tanto de las pocas salidas practicas viables fue el usar un modulo de apache para sobre-escribir estas rutas de los archivos .js tarea que en un inicio pensamos delegar al modulo mod_substitute, pero rápidamente nos dimos cuenta que las tareas de sustitución son limitadas a una sola expresión regular, por lo tanto necesitamos un modulo mas robusto y en este punto fue donde nos encontramos con este fantástico proyecto de Gilles Darold, mismo a quien damos todo el crédito posible y enlazamos para su consulta y apoyo.
Este modulo por decirlo de alguna forma nos permite realizar múltiples sustituciones sobre el contenido, lo cual resuelve en gran medida la problemática inicial. Su funcionamiento detallado lo pueden consultar en el enlace previo.
Una vez realizadas las sustituciones en tiempo real del contenido de las urls, nos encontramos con el detalle de los websocket, esto sería un detalle menor si no fuese porque la cámara transmite su video a través de websockets.
Esta limitante la resolvimos con el modulo mod_rewrite. Dicho lo anterior vamos a ver el ejemplo completo y a realizar los pequeños comentarios.
#Iniciamos con la definición de una variable la cual usaremos para trabajar sobre un subdirectorio de la url. Aquí asumimos que tendremos varias cámaras sobre el mismo virtualhost, accediendo de la siguiente forma: http://ip_o_dominio/cam1
Define path_cam1 cam1
#Seguidamente definimos un directorio sobre el cual haremos la definición del proxy reverso. <Location /${path_cam1}>
#Activamos el modulo RewriteEngine, este nos permitirá capturar la solicitud del websocket y dirigirla adecuadamente, esto es fundamental para el stream de video.
# Definición de las expresiones regulares, mismas que se encargarán de modificar el contenido para que sea posible acceder a la camara a través del proxy inverso.
#cerramos la definición del directorio </Location>
La anterior mecánica se debería replicar para todas las cámaras que se tengan.
NOTA: Esta re-escritura a sido probada en cámaras DH-IPC-HFW1431S1N-S4 V2.820.0000000.48, por lo tanto es probable que en otros modelos sean necesarias algunas modificaciones.
Por ultimo mencionar algunas herramientas utilizadas para lograr este objetivo:
tcpdump
Wireshark
Herramientas de desarrollador Mozilla Firefox
https://regex101.com/
Con esto finalizamos esta entrada, como siempre si hay alguna duda pueden contactarnos a través de nuestras redes sociales, whatsapp, telegram o nuestro menú de contacto en nuestra pagina web.
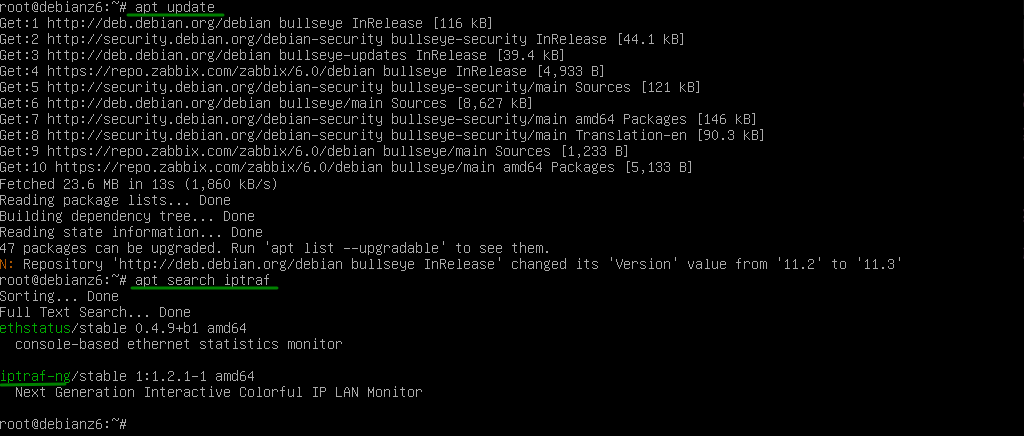
Una de las tareas mas básicas a la hora de la gestión de paquetes es la de buscar un paquete para instalar dentro del sistema; previamente aclarando que los repositorios deben de estar habilitados dentro del sistema y que el sistema debe alcanzar los mismos, por lo general están en internet.
Buscando un paquete en RHEL y derivados
Asumiendo que el sistema es un sistema reciente en donde nos apoyaremos mas que todo en la herramienta dnf, si es una distribución con algunos años deberíamos usar yum.
La búsqueda la hacemos con el siguiente comando asumiendo que no conocemos el nombre del paquete en su totalidad:
dnf search iptraf
Como podemos ver en la imagen anterior el gestor encontró un paquete que se llama iptraf-ng, lo cual en caso de ser lo que buscamos procederíamos a instalarlo.
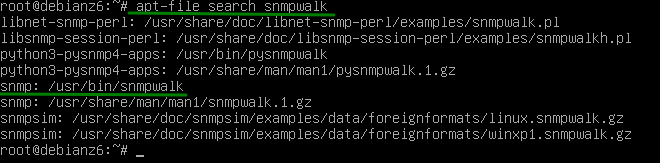
Otro caso que puede presentarse es que no conozcamos el nombre o descripción del paquete pero si un archivo que pertenezca al mismo, ejemplo, sabemos el nombre del binario pero no el del nombre del paquete, para esta tarea debemos ejecutar el comando dnf con la opción whatprovides y la ruta o comodín que se ajuste a la ruta, veamos un ejemplo para el programa snmpwalk
dnf what provides */snmpwalk
En este ultimo caso observamos que el paquete que contiene el programa snmpwalk es net-snmp-utils, el cual sería el paquete a instalar.
Buscando un paquete en Debian y derivados
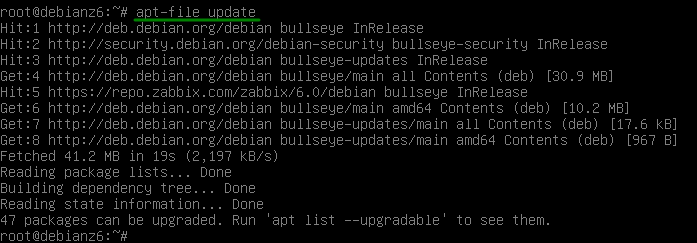
Como bien sabemos en debian y derivados tenemos la herramienta apt, la cual nos ayuda con la gestión del sistema dpkg, solo que en este caso hay un aspecto adicional a considerar y es que a diferencia que en dnf, apt no actualiza/verifica los repositorios cada vez que se usa el comando search, por el contrario en apt necesitamos primero ejecutar el comando apt update para actualizar los listados de los repositorios y posteriormente con la base de datos actualizada si realizar la búsqueda con el comando apt search, veamos un ejemplo.
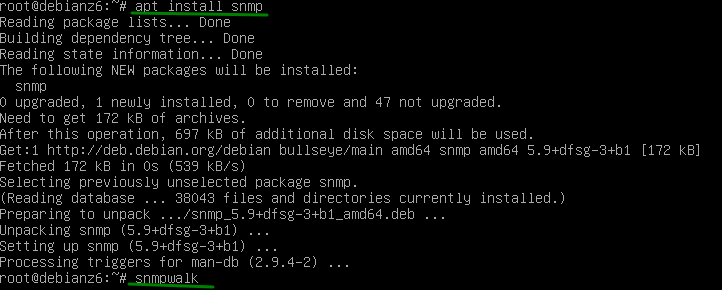
Ahora si lo que queremos es buscar un binario dentro de la paquetería, de igual forma que lo hicimos con dnf, necesitaremos instalar la herramienta apt-file y por su puesto tener la base de paquetes actualizada con apt-file update, seguido del comando apt-file search, veamos un ejemplo.
Con esto tendremos la utilidad instalada.
Ahora, esto es solo una pequeña parte de lo que estas dos herramientas nos permiten hacer, como siempre altamente recomendado consultar las paginas man de las herramientas que se revisaron en esta entrada dnf, apt, apt-file y adicionalmente rpm y dpkg.
Después de una pausa larga en nuestro blog, retomamos las entradas con conceptos básicos que nos pueden ayudar en el día a día, esta vez como asegurarnos que un paquete o programa esta instalado en nuestro sistema.
Lo primero que debemos tener en cuenta es tener claro que un paquete y un programa no son lo mismo.
Un paquete, es un conjunto de binarios, archivos de configuración y scripts, los cuales alimentan la base de datos del gestor de paquetes del sistema y estos mismos se copian al sistema de archivos.
Un programa, es un binario (o un script) que ejecuta instrucciones dentro del sistema, es posible encontrarlo dentro del sistema como un archivo con permisos de ejecución (los veremos al detalle en una entrada posterior).
Una vez teniendo claras las diferencias entre los dos veamos el primer caso:
1. Verificar si un paquete esta instalado dentro del sistema:
Es importante delimitar en este caso que solo nos vamos a referir a rpm y deb, no vamos a tener en cuenta otros gestores.
1.1 Basados en Red Hat
En Red Hat se cuenta con el sistema “rpm” (RPM Package Manager, anteriormente Red Hat Package Manager) , el cual controla la base de datos de los paquetes dentro del sistema, su ejecución se logra con el comando “rpm“.
Para verificar si un paquete existe podemos realizar una combinación de dos comandos rpm y el indispensable grep:
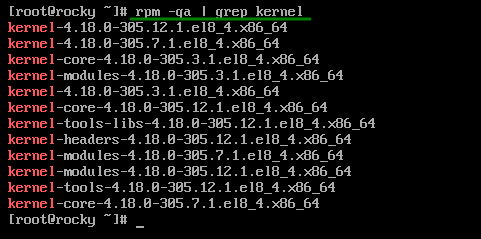
rpm -qa | grep kernel
Como lo podemos ver en la imagen nos muestra el paquete instalado con su versión instalada, en caso de no estar instalado el paquete en el sistema no nos mostraría nada.
los dos opciones que usamos con rpm son:
-q para hacer una consulta, combinado con
-a todos los paquetes instalados
Posteriormente pasamos ese resultado por una tubería a grep en donde especificaremos cual es el paquete que buscamos, en este caso “kernel“, obteniendo así el resultado de la consulta.
1.2 Basados en Debian
En debian contamos con el gestor “dpkg” (acronimo de Debian Package) el cual nos administra la base de datos de paquetes.
Para verificar la existencia de un paquete tendremos que ejecutar lo siguiente:
dpkg -l | grep kernel
Lo cual nos arroja la siguiente:
las dos primeros caracteres “ii” nos quiere decir el estado deseado y el estado real del paquete, sin profundizar en este momento, si el paquete esta instalado correctamente debería de estar “ii“.
En la siguiente columna tenemos el nombre del paquete
El siguiente sería la versión instalada.
La arquitectura para la cual esta generado el paquete.
Y por ultimo una breve descripción del paquete.
Antes de finalizar esta sección y si algún lector a llegado hasta este puntoy este perdiendo la cabeza porque no mencionamos a yum, dnf , apt o aptitude, esos son frontends para los gestores base, los cuales analizaremos por separado ya que merecen una entrada cada uno de ellos.
2. Verificar si un programa esta instalado dentro del sistema:
Cuando hablamos de un programa automaticamente tendremos que pensar en buscar un fichero y para ello vamos a hacer una pequeña introducción a find.
find es una herramenta altamente eficiente a la hora de hacer busquedas de todo tipo dento del sistema instalado.
Al usar find debemos tener en cuenta que buscaremos los nombres u otras caracteristicas del fichero y que se hará un recorrido por el sistema de archivos para verificar su existencia.
Un ejemplo rapido si queremos buscar la existencia del programa llamado “man”.
El parametro “/” quiere decir en que ruta buscaremos el archivo, en este caso estamos buscandolo en todo el sistema.
La opción “name” nos indica que estaremos buscando la palabra “man”
La opción “executable” nos buscara todos los ficheros que tengan permirsos de ejecución, en este caso nos dectanamos por esta opción y no por “perm” que tambien hubiese funcionado.
La opción “type” la cual nos indica que el nombre buscado debe ser de tipo archivo ya que dentro del sistema tambien pueden existir directorios o otro tipo de ficheros.
Otra opción sería utilizar el comando locate el cual no esta instalado en todas las distribuciones, pero basta con realizar un “locate man” para obtener el resultado de la busqueda.
Esto sería todo en esta entrada, no olvidar consultar las paginas man en donde podrán encontrar toda esta información y mucho mas detalle.
Si hay preguntas o comentarios pueden hacerlas en nuestras redes sociales: facebook o linkedin, hasta la próxima.
Las tareas de eliminación siempre me han parecido las mas emocionantes puesto que cuando son controladas te queda la satisfacción del buen uso del sistema, pero cuando son por errores la sensación de la adrenalina es imperdible.
Puesto que en la entrada anterior vimos como agregar un usuario al sistema, hoy vamos a ver como eliminar un usuario, para ello nos apoyaremos en la herramienta userdel.
Su uso es muy sencillo, tan solo tenemos que teclear el comando userdel mas el nombre del usuario que queremos eliminar, veamos un ejemplo básico.
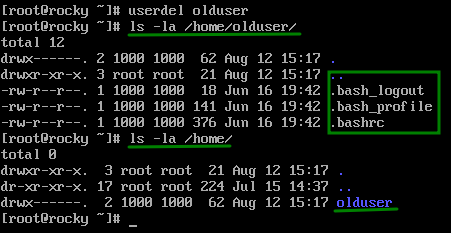
userdel olduser
Como podemos ver no pide confirmación y sin mas elimina el usuario, sin embargo si revisamos el directorio del usuario que acabamos de eliminar podemos ver que sus archivos aun existen.
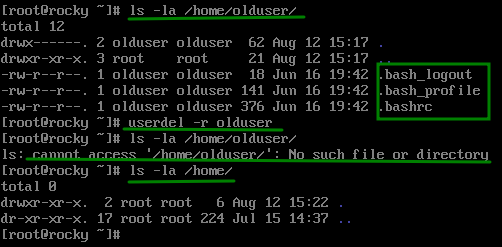
Para evitar este comportamiento debemos pasar la opción “-r” al comando para que nos elimine el home directory del usuario.
Algo importante para mencionar es que la opción -r NO elimina todos los archivos del usuario en el sistema, solo los que están dentro de su directorio de inicio, para poder borrar todos los archivos asociados al usuario debemos apoyarnos en herramientas de búsqueda de archivos, quizá la mas útil para esta situación es el comando find, el cual veremos en futuras entradas.
Ahora, si por alguna razón no queremos o podemos usar el comando userdel podemos optar por la opción manual que consistiría en eliminar las entradas en los archivos /etc/passwd, /etc/shadow, /etc/group y eliminar los archivos del directorio /home/usuario.
Esto sería todo en esta entrada, no olvidar consultar las paginas man en donde podrán encontrar toda esta información y mucho mas detalle.
Si hay preguntas o comentarios no olvidar hacerlas en nuestras redes sociales: facebook o linkedin, hasta la próxima.
Despues de un tiempo ausentes, regresamos con esta entrada en donde trataremos unas de las tareas mas basicas en las labores de adminsitración de cualquier sistema, el agregar un usuario al sistema; agregar un usuario no es tarea compleja pero como toda buena labor de administración debe ser conciente de los privilegios que se darán y las opciones que tenemos para controlar o personalizar al usuario.
El comando en su mínima expresión es “useradd nuevousuario“, veamos un ejemplo.
useradd akasistemas
Esto lo que hará de fondo es ingresar los siguientes registros en el sistema:
Primero: agrega la entrada en /etc/passwd, en donde se almacena la información del nombre del usuario, UID,GUID, el home directory y la shell que le asignamos.
Vamos a explicar muy brevemente que significa cada campo:
El primer campo es obvio que es el nombre así que no hay mucho que explicar.
el segundo campo en este y otros casos una “x”, es la contraseña encriptada, pero ya la explicaremos mas adelante, ya que esta guarda en otro archivo.
el primero número 1000 es el identificador numérico del usuario, este número es único dentro del sistema.
El segundo número 1000 es el identificador de grupo para el usuario y hacemos mención que al crear un usuario automáticamente se crea un grupo para el usuario, esto lo veremos mas adelante.
En este caso se dejo vacío pero este es el nombre del usuario detallado, en caso que lo hayamos especificado.
El home directory del usuario en donde se depositarán sus archivos personales y de configuración por defecto.
Y por ultimo la shell del sistema, muy importante este ultimo parámetro porque puede llegar la necesidad de crear un usuario dentro del sistema que no necesariamente acceda libre a la shell si no encapsularlo dentro de otro programa o sencillamente impedirle la entrada al sistema.
Segundo: agrega una entrada en el archivo /etc/shadow.
Veamos que significan cada uno de los campos.
Primero el nombre del usuario
Segundo el hash de la contraseña del usuario (el comando en si mismo no crear la contraseña, eso lo veremos en una entrada posterior dedicada al comando passwd).
Tercero la fecha del ultimo cambio de contraseña, esto expresado en unixtime días después desde el 1 de enero de 1970.
El número de días mínimo para que el usuario pueda cambiar la contraseña (0 significa deshabilitado)
El número de días en que la contraseña es valida.
El número de días en que el usuario será notificado antes de expirar la contraseña.
El número de días después de la expiración de la contraseña en que se deshabilitará la cuenta.
El número de días en unixtime que la contraseña será expirada.
Tercero: el archivo /etc/group.
Como podemos observar en este caso solo se tienen tres parámetros:
El nombre del grupo creado automáticamente.
La posibilidad de establecer una contraseña para el grupo, lo normal es que este en blanco.
el GUID del grupo mismo que concuerda con el establecido en el archivo /etc/passwd.
y por ultimo los usuarios miembros del grupo, los cuales pueden ser especificados y separados por comas.
Esto sería todo en esta entrada, no olvidar consultar las paginas man en donde podrán encontrar toda esta información y mucho mas detalle.
Si hay preguntas o comentarios no olvidar hacerlas en nuestras redes sociales: facebook o linkedin, hasta la próxima.
Como ya pudimos ver en una entrada anterior como agregar rutas en tiempo de ejecución al sistema, ahora es tiempo de ver como estas rutas pueden sobrevivir a un reinicio del sistema y veremos como hacer para Debian y derivados de Red Hat.
Primeramente revisaremos como hacer en plataformas RHEL, como bien sabemos las configuraciones de red en estos sistemas se almacenan en el directorio /etc/sysconfig/network-scripts así que nos resta crear un fichero especial llamado route-nombre_interfaz con lo cual el demonio de NetworkManager leerá y cargará estas rutas al sistema (recordemos que en versiones 8 de sistemas RHEL el demonio network esta desactivado por defecto en favor de NetworkManager), la sintaxis para especificar la ruta es muy sencilla, solo debemos de especificar la red destino via ip_enrutadora, veamos un ejemplo.
Ahora aplicaremos un reinicio al sistema y validamos.
Ahora es tiempo de ver como lo haríamos en un sistema Debian.
Recodemos que en este sistema las configuraciones se guardan en un único fichero /etc/network/interfaces, en este caso nos apoyaremos de la sub-instrucción up dentro del archivo de configuración, donde básicamente le estamos indicando que cuando la interfaz se este iniciando, ejecute la instrucción de carga de las rutas.
up ip r add 172.19.0.0/24 via 192.168.122.1
Veamos como quedaría en el archivo:
Reiniciamos la maquina para verificar la configuración:
Y bien de esta forma podemos agregar rutas permanentes a nuestros sistemas.
Y con esto terminamos la entrada de hoy, si tienes dudas al respecto no dudes hacerlas en nuestra página de facebook o linkedin.
Anteriormente habíamos liberado el webhook para zabbix-glpi, el cual en su momento solo soportaba la apertura de tcikets en glpi.
En esta ocasión realizamos mejoras al script y agregamos el soporte para creación, actualización y cierre automático de tickets. La nueva versión puede ser encontrada en el repositorio de github, mismo en donde se encuentra la primera versión.
Continuando con la sección de manipulación del stack de red iproute2 en GNU/linux, hoy vamos a revisar el como modificar las rutas del sistema en tiempo de ejecución.
Una de las primeras preguntas que nos podríamos hacer es, ¿y bueno, como para que quiero yo modificar rutas en el SO?, ¡Que lo hagan en el router o firewall, eso no me toca a mi! (un clásico por cierto o la aproximación, si alguien mas lo puede hacer que lo haga), aproximación perezosa, vamos a ver como hacer estos cambios que nos pueden sacar de problemas en algún momento.
Lo primero que debemos de tener en cuenta es que existe el concepto de ruta por defecto y ruta estática (aclaramos que esta entrada no es sobre protocolos de ruteo estilo BGP o OSPF), la ruta por defecto es única en el sistema, y las rutas estáticas pueden existir sin limite siempre y cuando no se contradigan entre si, otro aspecto a tener en cuenta es que para poder redirigir un trafico a otra ip esta debe de estar dentro del mismo segmento de red.
Con estos pequeños comentarios veamos como ver las rutas presentes en el sistema:
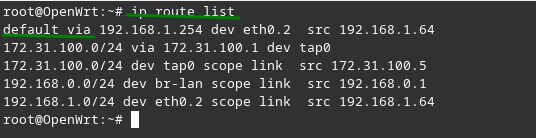
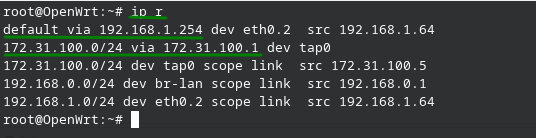
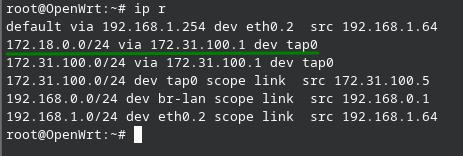
ip route list
La forma abreviada sería:
ip r
Podemos observar claramente la puerta de enlace por defecto “default via” y una ruta estática que tiene salida por la interfaz tap0, claramente la ip 172.31.100.1 debe ser alcanzable por el sistema.
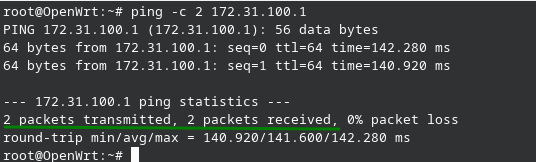
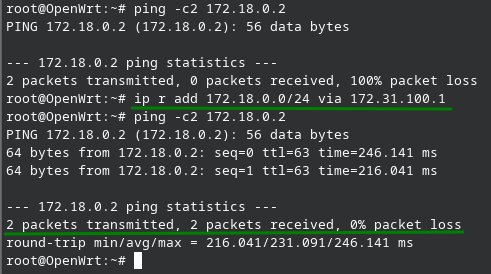
Ahora vamos a ver como podemos agregar una ruta estatica dentro del sistema, la instrucción se compone del comando base, mas la red que queremos alcanzar, mas el intermediario que nos permitirá ese acceso.
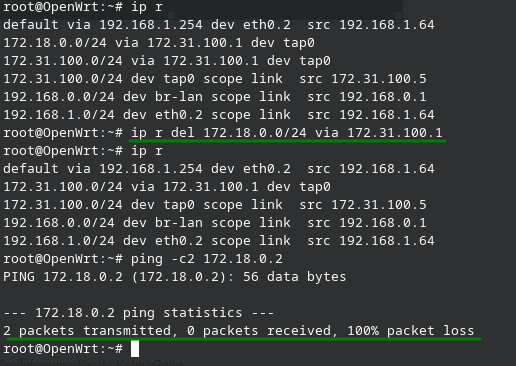
ip r add 172.18.0.0/24 via 172.31.100.1
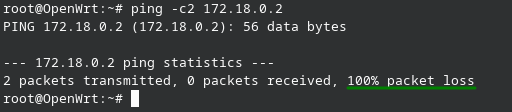
Primero validamos que no alcancemos el destino.
Ahora agregamos la ruta y validamos la conectividad
Revisemos como quedo nuestra tabla de rutas
Por ultimo para eliminar la ruta agregada lo unico que tenemos que hacer es dar la orden de borrar con la misma sintaxis del comando de agregar
ip r del 172.18.0.0/24 via 172.31.100.1
Y con esto terminamos la entrada de hoy, si tienes dudas al respecto no dudes hacerlas en nuestra página de facebook o linkedin.
Dicen que el diablo esta en los detalles, y en esta ocasión ese dicho nos cae a la perfección, en la entrada anterior vimos como agregar una ip a la tarjeta de red pero si la máquina se reinicia esta configuración se pierde, si le preguntamos a un entendido en GNU/Linux nos dirá algo similar a “en el fondo todos son lo mismo” y efectivamente, solo que en el intermedio es donde se hacen evidentes las diferencias para el caso que nos ocupa hoy y es el tema de la red.
Actualmente existen cientos de distribuciones, dentro de ellas hay tres que predominan, basados en Red Hat, Debian y Arch, hoy veremos como mantener cambios de red en Red Hat y Debian después de un reinicio, con el permiso de los usuarios de Arch.
Como bien sabemos en GNU/Linux todo dentro del SO se puede identificar como un fichero y las configuraciones de red no son la excepción, para Red Hat las encontraremos en el siguiente directorio:
/etc/sysconfig/network-scripts
y en Debian en la siguiente ruta:
/etc/network/interfaces
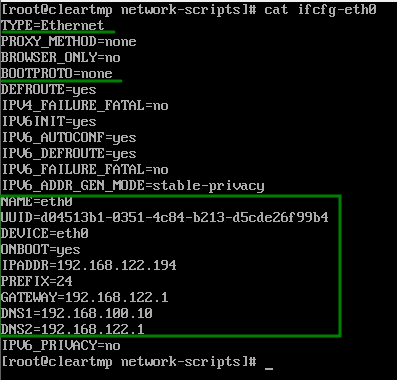
La primera gran diferencia que podemos ver es que Red Hat separa las configuraciones de las tarjetas de red en ficheros individuales y Debian lo hace todo en un solo fichero; antes que comencemos a emitir juicios veamos como quedaría una configuración básica en Red Hat:
Podemos observar que la configuración se hace bajo un modelo de asignación de variables.
Los valores que vale la pena explicar serían BOOTPROTO en donde le indicamos que NO use ninguno es decir se configurará a mano en el sistema operativo, el UUID el cual es un identificador único de la interfaz, recomendable mas no necesario.
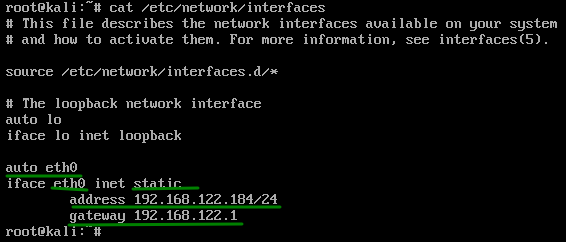
Ahora veamos en Debian
En este caso vemos que el modelo de configuración corresponde mas a una lectura de un fichero tabulado.
Otra de las grandes diferencias es que en Debian necesitamos especificar por separado los DNS del sistema, esto en el fichero /etc/resolv.conf
Algunos pensarán y bueno porque no usar NetworkManager directamente y usar comandos como nmtui y nos hace la vida mucho mas fácil, bien por dos razones primero el conocer el sistema lo mejor posible dentro de nuestras habilidades técnicas y otro hay ciertos softwares en los que NetworkManager se deshabilita por defecto debido a los problemas que genera, por estas razones es bueno conocer como y en donde modificar la configuración de la red, esto claro sin dejar de lado el uso de las anteriores herramientas cuando nos sea posible.
Y así terminamos la entrada de hoy, si tienes dudas al respecto no dudes hacerlas en nuestra página de facebook o linkedin.